通过单阶段监督微调与强化微调结合粤有钱,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。
中国科学院自动化研究所深度强化学习团队联合美团,提出一种单阶段监督 - 强化微调方法—— SRFT ( Supervised Reinforcement Fine-Tuning ) 。该方法通过基于熵的动态加权机制,将两种训练范式结合。

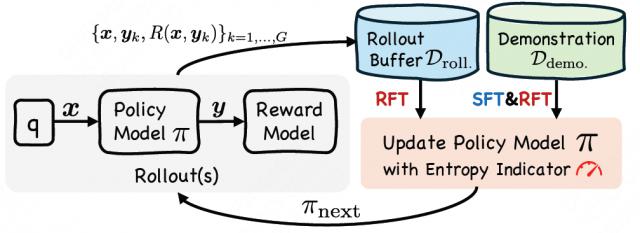
图注:SRFT 方法示意图,展示了对探索试错(rollout)数据和演示(demonstration)数据的协同学习,以及平衡监督和强化信号的熵感知策略更新。
在大语言模型(LLM)的推理能力提升上,监督微调(SFT) 和强化学习(RL,有时也称作强化微调,RFT)是两条核心技术路线。但它们各自都存在瓶颈:
SFT 擅长模仿专家解题思路,类似"背书",能快速为模型打下基础,但缺点是容易陷入死记硬背,缺乏在新问题上灵活应用和寻找最优解的能力;
RFT/RL 通过不断试错来探索解题方法,类似"刷题",能够发现更优解法,但其探索过程效率低下,容易面临模式崩溃风险。
因此,目前研究者通常采用两阶段顺序方法 SFT → RFT/RL:先用 SFT 学习高质量数据集,再用 RFT/RL 进一步优化对齐 LLM 策略(即先"背完书"再"去刷题")。
然而,这种串行方式不仅影响学习效率,还常常导致模型在"刷题"时忘了"书本"上的知识,引发知识遗忘等问题,如何让两者在同一阶段协同作用,做到"边背边练",成为提升 LLM 推理能力的关键之一。
结果显示,SRFT方法能够同时从高质量演示数据(demonstrations)与 LLM 自身的探索试错 ( rollouts ) 中学习,在 5 项数学推理任务中实现59.1%的平均准确率,较 zero-RL 基线提升9.0% ;在三项分布外任务上取得62.5%的平均准确率,较 zero-RL 基线提升10.9% ,展现了卓越的泛化能力。
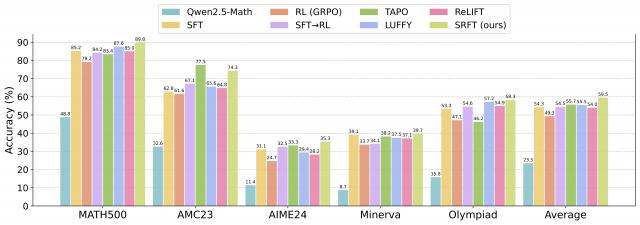
△SRFT 与其它算法的性能对比分析:面向 LLM 推理的 SFT 和 RL
研究团队首先对 SFT 与 RL 在 LLM 微调中的作用进行了分析,并深入探究了二者结合的有效路径。
SFT 和 RL 对 LLM 的作用:大锤 vs. 手术刀
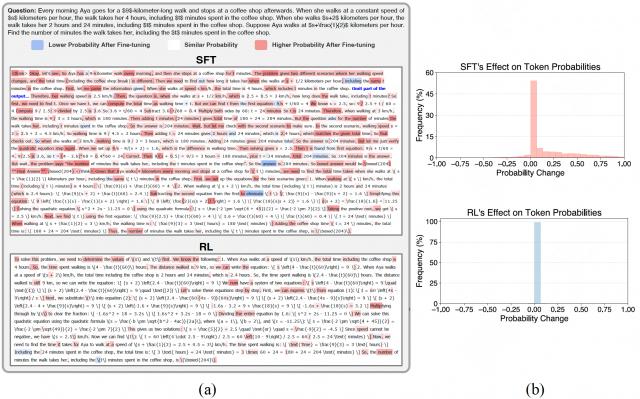
图注:LLM 微调前后分布可视化, ( a ) SFT 与 RL 前后分布改变示例 ( b ) 在 5 个数据集上统计了分布变化的频率。
通过对微调前后模型对 token 概率的改变进行可视化,仔细分析实验结果,可以得到以下发现:
SFT 导致大部分 token (50% 以上)的概率分布改变(粗粒度)
RL/RFT 只对特定 token (少于 2%)进行有针对性的调整,同时保留了大部分内容(细粒度)
从理论上看,SFT 的目标是最大化专家数据的似然,将专家演示的条件概率分布 "注入" 模型,类似人们通过"背书"学习,其梯度公式揭示了其内在机制:
该公式表明,对单个样本训练,SFT 主要通过提高目标标记的概率,同时降低词汇表中所有其他标记的概率,这会锐化模型的分布,从而产生更具确定性的输出。 通过这种"一刀切"的方式,SFT 强制模型去拟合专家数据,但也可能因此抑制模型的探索性和多样性。
训练动态可视化如下图所示,数字表示训练后的准确率。SRFT 通过在结合两种方法实现直接优化,到达与 SFT → RL 接近的区域,且无需两阶段转换。
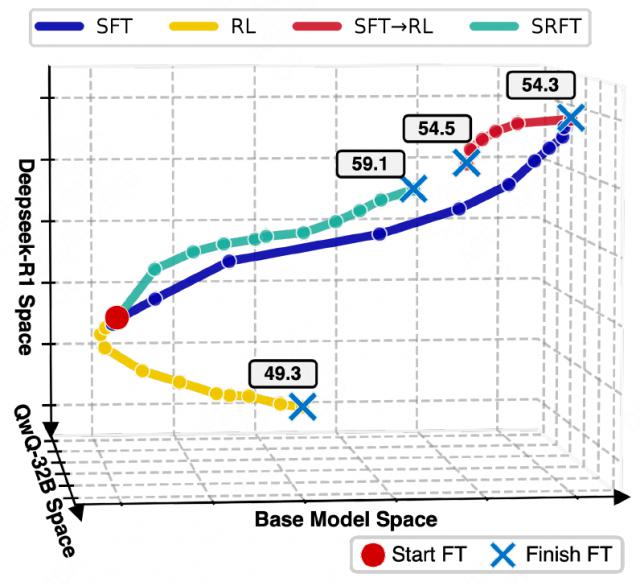
为了进一步探究训练动态,研究人员还从模型训练轨迹的角度对几种微调方法进行了可视化。论文提出了一种新颖的可视化方法。其核心思想是:
将不同模型看作高维空间中的点,通过计算它们在生成相同回复(response)时输出 token 概率分布的"距离",来描绘其在训练过程中的"移动轨迹"。
具体而言,论文引入了三个参考模型——基础模型(Qwen-2.5-Math-7B)、DeepSeek-R1 和 QwQ-32B 作为坐标系,通过模型与参考模型回复的 teacher forcing 距离来间接测量模型在不同微调步骤中的训练动态(如果两个模型对所有提示(prompt)中的所有回复 token 分配相似的概率,则认为它们是接近的)。
结果表明,所有微调范式在提升性能的同时,均会偏离基础模型空间,此外:
SFT 使模型在概率空间中移动的距离最远,印证了其"大锤"般的全局性影响。
SFT → RL 的两阶段路径揭示了一个问题:SFT 可能将模型推得"过远",后续的 RL 反而需要将其"拉回"到离基础模型更近的区域才能达到最优,这暗示了串行方法的低效性。
SRFT 的单阶段路径则显得更为直接和高效,它在学习专家知识的同时,没有过度偏离初始模型,从而实现了更精准的优化。
结合两种范式:从两阶段到单阶段粤有钱
熵是信息论中的一个重要概念,它衡量的是随机变量的不确定性。在 LLM 的推理过程中,熵可以反映模型输出分布的不确定性,近期的诸多工作也展示了熵在 LLM 训练中的重要性。
高熵表示模型的输出分布较为均匀,不确定性较大;低熵则表示模型的输出分布较为集中,不确定性较小。
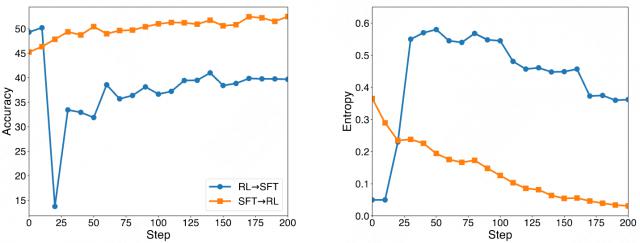
图注:两种结合方式的性能、熵变化曲线
在该论文中,研究人员主要从SFT 和 RL 结合的角度对熵展开了分析,如上图所示。 在 RL 后进行 SFT,会使模型的熵短暂增加,这表明模型在学习新的知识和模式时,其输出分布变得更加不确定。
随着训练的进行,熵逐渐降低,模型逐渐收敛,输出分布变得更加确定,最终提升模型性能。
相比之下,RL 在训练过程中则会使熵显著降低,模型的输出分布变得更加集中。这是因为 RL 通过奖励函数引导模型学习特定的策略,使模型更倾向于生成能够获得高奖励的输出。然而,这种低熵的状态也可能导致模型的可塑性降低,限制了后续训练的效果。
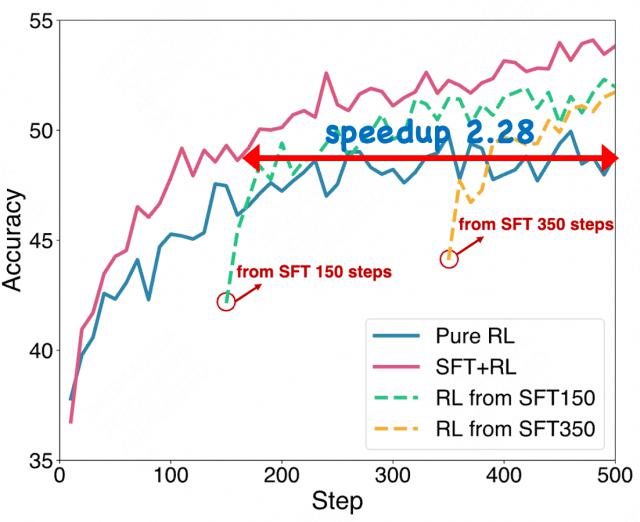
图注:不同结合方式的训练效率
论文接着比较了纯 RL、不同 SFT 步数的顺序 SFT → RL 方法,以及单阶段 SFT+RL 方法。结果表明,与顺序 SFT → RL 方法相比,单阶段 SFT+RL 方法实现了更优的训练效率。单阶段 SFT+RL 方法通过统一优化有效利用演示数据,提速2.28 倍。这种方法能够直接针对目标进行策略优化,同时保留从数据集中通过监督学习进行知识蒸馏的优势。
方法:监督强化微调(SRFT)
本论文提出 SRFT ( Supervised Reinforcement Fine-Tuning ) ,将监督微调 ( SFT ) 和强化学习微调 ( RFT/RL ) 单阶段结合。以下是对方法的描述:
核心思想
SRFT 的核心在于其单阶段学习机制:通过 SFT 实现粗粒度行为策略逼近,通过 RL 实现细粒度策略精化,借助于单阶段训练,将微调同时应用于演示数据和自生成的试错数据。
从演示数据 ( demonstration ) 中学习双重策略设计
对于包含演示数据的数据集 (例如,由 DeepSeek-R1 生成的推理响应),SRFT 采用双重策略来有效利用这一宝贵资源:
1. 监督微调组件
通过 SFT 执行行为策略的粗粒度逼近:
2. 异策略强化学习组件
采用类似 LUFFY 的异策略强化学习(off-policy RL)方法,将演示数据作为高质量的异策略强化学习数据,进行细粒度学习:
直接将 LLM 的同策略强化学习(on-policy RL ) 探索试错的组(group)与演示数据结合,创建增广训练组:
整个增广训练组的优势估计为:
分布不匹配缓解策略
为解决演示数据的行为策略 与当前训练策略 之间的分布不匹配,引入两种关键缓解策略:
1. 熵感知自适应权重机制
对于演示数据的 SFT,引入基于当前策略熵的自适应权重机制:
当模型熵很高(非常不确定)时,SFT 权重 很小。这能防止模型在"迷茫"时被专家数据过度"带偏",避免了分布不匹配带来的负面影响。最终的演示 SFT 损失为:
2. 重要性采样
对于异策略强化学习训练,引入类似 GRPO 和 PPO 的重要性采样项修正分布差异。最终的异策略强化学习训练损失为:
其中重要性采样比率为:粤有钱
为简化实现,论文设置 并省略截断操作。
从自探索(self-exploration)中学习 RL 目标函数分解
在具有二元奖励 的 RL 范式下,其目标函数可以自然分解为两个不同组件:
其中:
正样本目标:类似于监督微调,最大化正确响应的似然
负样本目标:实施似然最小化,减少分配给错误响应的概率
熵自适应权重
为保持训练稳定性并防止熵的快速降低,对正样本目标引入熵自适应权重机制:
完整的自探索目标为:
单阶段集成方法统一损失函数
通过同时利用演示数据和自探索试错数据,SRFT 有效平衡了 SFT 的粗粒度调整与 RL 的细粒度优化。总损失函数结合了所有四个组件:
关键机制总结
1. 熵感知权重:两种熵感知权重机制确保训练稳定性
:当策略展现高熵(不确定性)时,权值降低,减少 SFT 对训练的影响
:当熵较高时,使 RL 训练中正样本训练的权值上升,使熵下降,从而促进熵的稳定
2. 单阶段优化:直接朝着目标函数优化,同时保持来自数据集的监督学习的知识蒸馏优势
这种方法使 SRFT 能够同时从演示数据和自探索试错数据中受益,同时通过两种熵感知权重机制保持稳定的训练动态。
结果:性能显著优于 zero-RL 方法,与其它结合方法相比提升明显关键发现
主要实验结果(包含 5 个数学推理基准和 3 个非数学基准):
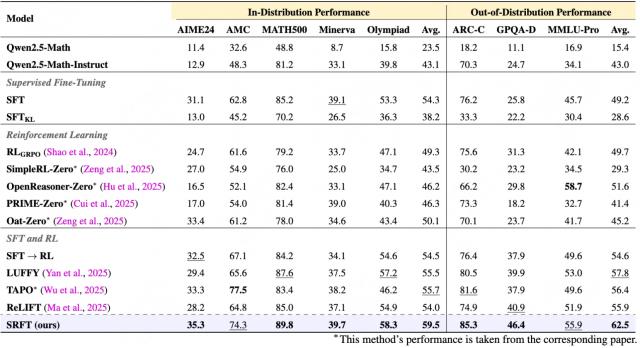
仔细分析 SRFT 与 SFT、RL 以及 SFT 与 RL 结合相关方法的性能比较,可以得到以下发现:
显著性能提升:
SRFT 在五个挑战性竞赛级推理基准上取得了59.1% 的平均准确率
比最佳 zero-RL 基线方法提升了+9.0 个百分点
比 SFT 方法提升了+4.8 个百分点
比 SFT+RL 组合方法提升了+3.4 个百分点
泛化能力优秀:
平均分数 : SRFT 取得 62.5 分,比最佳基线提升+4.7 个百分点
跨域表现 : 在所有三个分布外基准上都表现出色
训练动态分析:更稳、更长、更高效
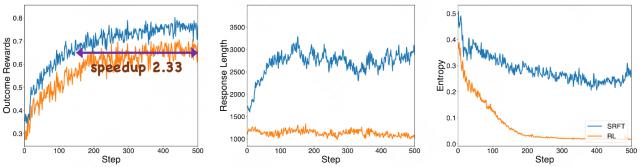
△训练动态曲线(奖励、回复长度、熵)
训练奖励动态
SRFT 相比纯 RL 实现了更快的性能改进,提速2.33 倍
两种方法都显示出训练奖励的上升趋势
SRFT 的收敛更加稳定
响应长度变化
RL:
倾向于生成更简洁的响应
SRFT:
显示出响应的逐步延长,表明发展出更全面详细的推理过程
推理质量:
响应长度的增加表明模型发展出更深入的推理过程
训练熵动态
RL:
表现出快速的熵下降
SRFT:
维持更稳定的熵,表明策略能够在训练期间继续探索
训练稳定性 :
熵感知权重机制的有效性得到验证
总结
该工作分析探究了SFT 与 RL 在 LLM 推理任务中各自的特点与结合方式,提出的 SRFT 方法通过基于熵的权重机制实现了 SFT 与 RL 的单阶段结合。SRFT 成功地在单阶段训练流程中实现了知识学习(SFT)与自主探索(RFT/RL)的动态平衡 ,在多项任务上取得了推理性能和泛化性能双提升。
更多研究细节,可参考原论文。
项目网页 : https://anonymous.4open.science/w/SRFT2025
论文链接 : https://arxiv.org/abs/2506.19767
模型链接 : https://huggingface.co/Yuqian-Fu/SRFT
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
� � 点亮星标 � �
科技前沿进展每日见粤有钱
迎客松配资提示:文章来自网络,不代表本站观点。


沪深京指数
热点资讯
